

What Is Star Schema In Data Warehouse
What is a star schema
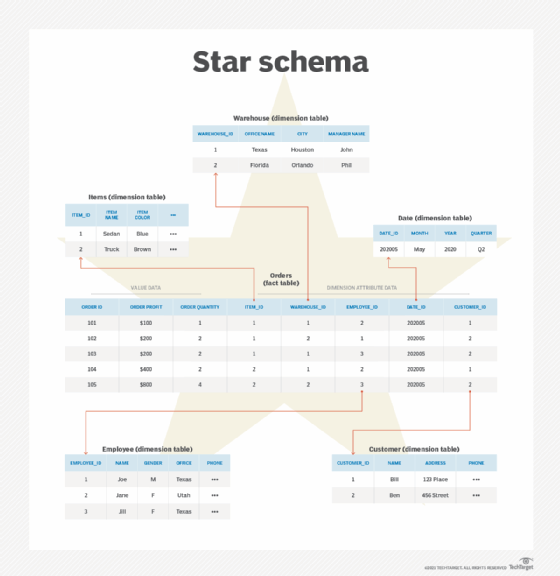
A star schema is a database organizational construction optimized for use in a data warehouse or business intelligence that uses a single large fact table to store transactional or measured data, and 1 or more smaller dimensional tables that store attributes well-nigh the information. It is called a star schema because the fact table sits at the center of the logical diagram, and the pocket-size dimensional tables branch off to form the points of the star.
A fact tabular array sits at the middle of a star schema database, and each star schema database only has a single fact tabular array. The fact table contains the specific measurable (or quantifiable) primary data to be analyzed, such as sales records, logged performance data or financial data. It may be transactional -- in that rows are added as events happen -- or it may be a snapshot of historical data up to a point in time.
How a star schema works
The fact table stores two types of information: numeric values and dimension attribute values. Using a sales database as an case:
- Numeric value cells are unique to each row or data point and do not correlate or relate to data stored in other rows. These might be facts about a transaction, such as an social club ID, total amount, internet turn a profit, order quantity or exact fourth dimension.
- The dimension aspect values practice not directly shop data, simply they store the foreign primal value for a row in a related dimensional table. Many rows in the fact table will reference this type of data. So, for instance, it might store the sales employee ID, a date value, a product ID or a branch office ID.
Dimension tables store supporting information to the fact tabular array. Each star schema database has at least one dimension table, only will often have many. Each dimension tabular array will relate to a column in the fact table with a dimension value, and will store additional data about that value.
For instance:
- The employee dimension table may use the employee ID as a cardinal value and tin can contain data such as the employee's name, gender, address or phone number.
- A product dimension table may store data such as the production name, manufacture cost, colour or first date on market.
Organizations should carefully construct a star schema. Each table should have either fact data or dimension data, and avoid mixing the ii. Consider the total number of dimension tables to maximize performance. Also, consider the granularity of the data captured to optimize for the types of queries that will exist run. For example, decide if the exact time should be used or just the date, or if the monetary values should be recorded to the dollar or rounded to the thousandth place.
Optimized for querying large data sets, information warehouses and data marts, star schemas back up online analytical processing (OLAP)cubes, analytic application, ad hoc queries and business intelligence (BI). They besides support count, sum, average and other rapid aggregations of many fact records. Users can filter and group (sliced and diced) these aggregations by dimensions. For example, users tin generate queries such as "discover all sales records in the month of June" or "get the total revenue for the Texas part from 2020" chop-chop.
Star schema vs. snowflake schema
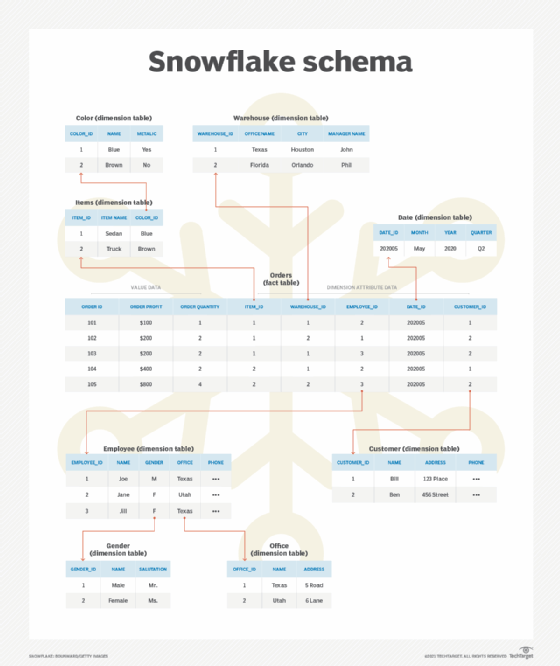
Star schema'due south dimension tables do not contain any foreign keys. That is, the dimension tables do not reference any other tables, nor practice they have whatsoever "sub-dimension tables." They are generally denormalized because some information may be duplicated in the dimension tables. This allows star schema databases to exist optimized for read and query performance forth specific dimensions.
A snowflake schema database is similar to a star schema in that it has a single fact tabular array and many dimension tables. Notwithstanding, for a snowflake schema, each dimension table might have foreign keys that chronicle to other dimension tables.
And then, in a star schema there is no further branching from each dimension table. But in a snowflake schema each branch might take further branches -- like a snowflake with each branch having successively smaller branches coming out of a primal cadre in a fractal pattern. A snowflake schema is also more normalized than a star schema, though non necessarily fully normalized.
As a unproblematic case, the sales record in the fact table contains an employee ID. This employee ID relates to an employee dimension tabular array that contains data such equally the starting time name, last proper name, gender and branch office.
- In a star schema, the record would contain information such equally "male" and "Texas Part." This would be duplicated information also in other rows for employees with the same gender or branch office.
- In a snowflake schema, the gender or co-operative office would contain a foreign central value to a gender dimension table and a branch function dimension tabular array. These could contain information such every bit gender, name, salutation (Mr. or Ms.), branch office name, co-operative office accost or branch managing director.
Star schema pros and cons
In that location are several pluses and minus to using star schema.
Star schema pros
- uncomplicated design;
- fast read and queries;
- easy data aggregation; and
- easy integration with OLAP systems and data cubes.
Star schema cons
- redundant data makes for larger storage on disk;
- potential for data abnormalities, errors and inconsistencies;
- slower queries;
- express flexibility on non-dimensional information.
Star schema employ cases
Star Schema databases are best used for historical data.
This makes them work most optimally for data warehouses, data marts, BI utilise and OLAP. Primarily read optimized, star schemas will deliver good functioning over large data sets. Organizations tin can likewise tailor them to provide their best performance forth the specific criteria considered the about important or most used to query confronting. Information tin can be added transactionally as information technology comes in, or it can exist batch imported then checked and properly denormalized at that time.
Star schema database structures are more often than not not a good fit for live data, such equally in online transaction processing. Their denormalized nature imposes restrictions that a fully normalized database does not. For example, slow writes to a customer order database could crusade a slowdown or overload during loftier customer activity. This potential for data abnormalities could be disastrous in a alive order fulfillment system.
This was last updated in May 2021
Continue Reading Nigh star schema
- Data warehouse environment modernization tools and tips
- New data warehouse schema blueprint benefits business users
- Open source database migration guide: How to transition
- A quick rundown of 3 layered compages design styles
Dig Deeper on Data integration
-

Coagulate launches with information transformation platform

Past: Sean Kerner
-

data modeling

By: Craig Stedman
-

seven information modeling techniques and concepts for business

By: Rick Sherman
-

analytic database

What Is Star Schema In Data Warehouse,
Source: https://www.techtarget.com/searchdatamanagement/definition/star-schema
Posted by: walkerfaingentine.blogspot.com
0 Response to "What Is Star Schema In Data Warehouse"
Post a Comment